In-Context Learning & Chain-of-Thought Prompting
Ⅰ. In-Context Learning과 성능 향상
In-Context Learning은 언어 모델의 prompt에 task에 대한 묘사적인 설명문을 입력하여, 이를 토대로 학습하도록 유도하는 방법을 말한다. 직접적인 parameter의 업데이트 없이도 가능한 학습이므로, fine-tuning 및 데이터 수집에 필요한 비용을 절약할 수 있다는 장점이 있다. In-Context Learning의 대표적인 방법은 예시(demonstration)을 제시하는 것이다. 이때 예시가 아예 없으면 ‘Zero-shot’, 예시를 한 개 제시하면 ‘One-shot’, 예시를 두 개 이상 제시하면 ‘Few-shot’이라고 한다. 선행 연구에 따르면 언어 모델의 성능은 Few-shot일 때가 가장 좋고, 그 외에는 One-shot일 때가 Zero-shot일 때보다 좋다고 한다. 즉, 예시의 수가 많을수록 언어 모델의 성능이 향상된다는 것이다.
본 연구는 In-Context Learning이 실제로 언어 모델의 성능 향상에 도움이 되는지 알아보고자 하였다. 이에 세 가지의 prompting setting(One-shot, Three-shot, Five-shot)을 구성하여 GPT에게 자연어 형태의 수학 문제를 50문항 풀어보게 하였다. 정확도의 일종인

를 평가 지표로 삼아, 각 setting에서의 성능을 측정/비교하였다. 결과가 경향성이 있고 일반화 가능함을 보이기 위해, 앞의 과정을 총 세 차례 반복하여 1~3회차로 명명하였다. 전체 결과는 아래와 같다.

표를 보면, GPT에게 주어지는 예시가 많아질수록 GPT의 정확성도 높아진다는 것을 알 수 있다. 예컨대 One-shot일 때는 1~3회차의 평균점수가 0.0533점에 불과하지만, Three-shot일 때는 0.18점이 되어 평균점수가 3배 넘게 상승한다. Three-shot에서 Five-shot으로 늘렸을 때에도, 소폭이기는 하나 평균점수는 0.2033점으로 또다시 상승한다. 1회차에서 3회차까지의 시행 모두에서, 하나의 예외도 없이, 예시의 수가 늘어날수록 정확도도 올라가는 것으로 보아, In-Context Learning이 GPT의 성능을 향상시킨다고 볼 수 있을 것이다. 다만 Three-shot에서 Five-shot으로 늘렸을 때 상승치가 미미하다는 점을 고려하면, 성능 향상의 한계치는 존재할 것이다. 즉, 예시를 늘린다고 성능이 무한히 향상되는 것은 아닐 것으로 생각된다.
Ⅱ Chain-of-Thought Prompting과 성능 향상
Ⅰ장에서 In-Context Learning이 언어 모델의 성능을 높일 수 있음을 보인 바 있다. 예시의 수를 늘릴수록 성능이 좋아졌으나, 0.22점이 한계치였다. 그렇다면, parameter의 조정 없이 In-Context Learning만으로 성능을 더 올리는 것은 불가능할까? Wei, Jason 등 선행 연구자에 따르면, Chain-of-Thought Prompting(이하 ‘CoT Prompting’)으로 추가적인 성능 향상이 가능하다고 한다. CoT Prompting은 In-Context Learning의 일종으로, 언어 모델이 중간 추론 단계를 거치도록 유도하는 prompting 방식을 말한다.
Ⅱ장에서는 CoT Prompting이 실제로 일반적인 In-Context Learning(이하 'Direct Prompting')에 비해 성능이 높은지 알아보았다. Ⅰ장에서와 마찬가지로 세 가지의 prompting setting(One-shot, Three-shot, Five-shot)을 구성하여, GPT에게 같은 데이터셋의 문제를 풀어보게 하였다. 이때 CoT Prompting이 적용된 예시를 제시하였다. 이렇게 도출된 1~3회차의 결과를 Ⅰ장에서 Direct Prompting으로 도출된 1~3회차 결과와 비교하였다. 동일한 점수 체계를 사용하였으며, 전체 결과는 아래와 같다.
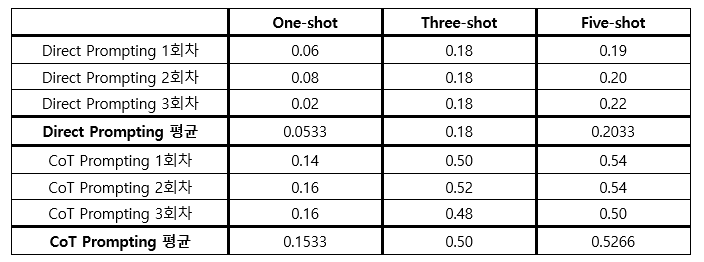
결과를 보면, CoT Prompting이 Direct Prompting을 크게 앞지르는 것을 확인할 수 있다. 예컨대 CoT Prompting은 One-shot일 때부터 이미 평균점수가 0.1533에 달하지만, Direct Prompting은 Three-shot일 때에도 0.18점으로 CoT Prompting의 One-shot 점수와 격차가 거의 없다. 또한 CoT Prompting의 Three-shot 평균 점수는 0.50점으로, Direct Prompting에서의 최고점수 0.22점보다도 약 2.5배 높다. 이처럼 세 번의 시행 모두에서, 그리고 One-shot, Three-shot, Five-shot 모두에서, CoT Prompting의 점수가 Direct Prompting의 점수보다 월등히 높은 것으로 보아, CoT Prompting이 Direct Prompting보다 뛰어나다고 할 수 있을 것이다.
왜 CoT Prompting이 Direct Prompting보다 우수할까? 최종 답을 곧바로 제시하는 Direct Prompting은 암산과 같아서 오류가 잦지만, 중간 추론 과정을 거치는 CoT Prompting은 풀이 과정을 찬찬히 적어가는 것과 같아 정확도가 올라가기 때문이다. 예컨대 “Carlos is planting a lemon tree. The tree will cost $90 to plant. Each year it will grow 7 lemons, which he can sell for $1.5 each. It costs $3 a year to water and feed the tree. How many years will it take before he starts earning money on the tree?"라는 문제가 주어졌을 때, Direct Prompting은 풀이과정 없이 정답만 제시하면서도 1~3회차 내내 한 번도 정답을 맞히지 못했다. 반면 CoT Prompting은 “It will take Carlos <<90/12=7.5>>7.5 years before he starts earning money on the lemon tree. He will earn $7.5 (7 lemons x $1.5) in profit each year, minus the $3 for water and feeding, for a net profit of $4.5 per year.”와 같이 풀이과정을 통해 문제를 푸려고 하였기 때문에, Three-shot부터는 대부분 정답을 맞히었다.