경제학코딩1 – Final Project: Part 2
본 글은 경제학코딩1의 Final Project에 대한 글이다.
Part1에 이어 Part2의 내용에 대해 알아보겠다.
Part1은 아래의 링크에서 확인할 수 있다.
https://helloeconomistkim.tistory.com/27
4. 이후, preprocess function을 정의하였다. function의 정의 과정에서 주목할 점은 두 가지이다. 첫째, sent0부터 sent136까지가 string형태의 데이터이기 때문에, for 방식을 통해 sent0~136을 하나로 join 시켰다. 둘째, 값이 Nan이나 <PAD>로 뜨는 경우가 있어, 오류를 방지하기 위하여 해당 값들은 join에서 제외시켰다.
function의 정의가 끝난 후, 해당 function을 soccer 전체에 적용시키기 위해, map method를 사용하였다.

5. 이어서 group_texts function을 정의하였다. token sequence의 길이가 너무 길면, 모델을 무겁게 하여 Colab에서의 훈련이 불가능해지므로, block_size를 설정하여 sequence의 최대 길이를 정해주었다. block_size를 1000, 500, 300으로도 해보았으나, 그렇게 할 경우 Colab의 성능 부족으로 error가 발생하였다. 이에 error를 발생시키지 않으면서도 최대한 큰 숫자인 200을 block_size로 정하였다.
function의 정의가 끝난 후, 해당 function을 soccer 전체에 적용시키기 위해, map method를 사용하였다.

6. 마지막으로, pytorch의 trainer를 통해 최종적으로 finetuning을 하였다. 데이터셋의 크기에 따라, 최소 1분에서 최대 50분의 시간이 소요되었다.

(4) 성능 비교
사용된 데이터셋의 종류와 데이터의 크기에 따라, 최종적으로 3가지 계열의 모델을 구현하였다.
첫 번째 모델은 ‘my_awesome_eli5_clm-model’으로, eli5 데이터셋을 사용한 모델이다. 따로 축구에 특화되지 않은 standard하고 general한 모델이다.
두 번째 모델은 ‘soccer_finetuned_model_final’ 계열의 모델들이다. socce_report_analysis 데이터셋을 사용했다. 훈련에 사용된 데이터의 양을 조절하여, final 1부터 final5까지 5개의 모델을 만들었다. final5가 가장 성능이 좋아 final5만을 보이겠다.
세 번째 모델은 ‘soccer_finetuned_model2_final’ 계열의 모델들이다. soccer-dialogues 데이터셋을 사용했다. 이 역시 훈련에 사용된 데이터의 양을 조절하여, final1부터 final5까지 5개의 모델을 만들었다. 독특한 특징이 있어 final1~final5 모두를 보이겠다.
이 세 가지 모델들의 성능을 비교하고자 한다. 비교를 용이하게 하기 위하여, prompt는 “Manchester United is having a great season so far.”로 통일시켰다. 또한 출력값의 maximum length는 50자로 제한하였다.
1. my_awesome_eli5_clm-model (eli5를 사용한 모델)
3가지 모델 중 문장이 가장 매끄러운 것을 확인할 수 있다. 그러나 prompt의 맥락과 전혀 안 맞고, 심지어는 축구 관련 내용도 전혀 없다. 따라서 문장의 완결성은 뛰어나나, 축구에 대한 이해는 전무하다고 할 수 있다.

2. soccer_finetuned_model_final (socce_report_analysis를 사용한 모델)
문장이 지나치게 길어지고, 쉼표가 없는 등 다소 매끄럽지 않은 부분들이 보인다. 그러나, prompt의 맥락을 어느 정도 이해한다는 것을 볼 수 있다. 특히 첫 번째 출력값의 경우, ‘manchester united가 좋은 시즌을 보내고 있다’는 맥락에 정확하게 일치하는 내용을 포함하고 있다. 두 번째 출력값은 어느 정도 맥락에 맞기는 하나, ‘13경기에서 7게임을 졌다’는 문장도 포함되어 다소 앞뒤에 안 맞는 부분도 있다. 세 번째 출력값은 축구와 관련된 내용이기는 하나, 문맥과는 전혀 관련 없는 내용이다. 전반적으로 봤을 때, 문장의 완결성은 가장 떨어지나, 축구에 대한 이해도가 높고, 축구 관련 맥락을 파악하는 능력이 상당하다고 할 수 있다.


3. soccer_finetuned_model2_final 계열 (soccer-dialogues를 사용한 모델들)
final1부터 final5까지의 성능이 크게 차이나는 것을 볼 수 있다.
final1은 train set을 400줄, test set을 100줄로 하였다. 훈련 데이터의 크기가 턱없이 작아, 확실히 성능이 부족함을 확인할 수 있다. 50자의 max_length를 다 채우지 못하고 있으며, prompt의 맥락에 대한 파악이 전혀 이루어지고 있지 않다. 다만 축구에 대한 내용이기는 하다.
final2는 train set을 40000줄, test set을 10000줄로 하였다. 훈련 데이터의 크기를 크게 늘렸기에 좋은 성능의 모델을 기대하였으나, 문장이 제대로 출력되지 않았다. 각 글자 사이마다 간격을 띄워 놓아, 제대로 된 단어도 구성해내지 못했다. 정확한 원인을 파악할 수는 없었지만, tokenizer와 관련한 오류가 있는 것으로 추측된다.
단어 간 간격 문제는 무시하더라도, “goals 1 Sandro _ Binglive caps 26s and”라는 문장은 축구와 관련되기는 했으나 맥락과 전혀 관련이 없는 내용이다. 따라서 여전히 맥락 파악이 되지 않음을 알 수 있다.
final3은 train set을 40줄, test set을 10줄로 하였다. 데이터의 크기가 너무 작아 당연히 훈련이 제대로 이루어지지 못했고, 그 결과 아무런 문장도 출력해내지 못했음을 알 수 있다.
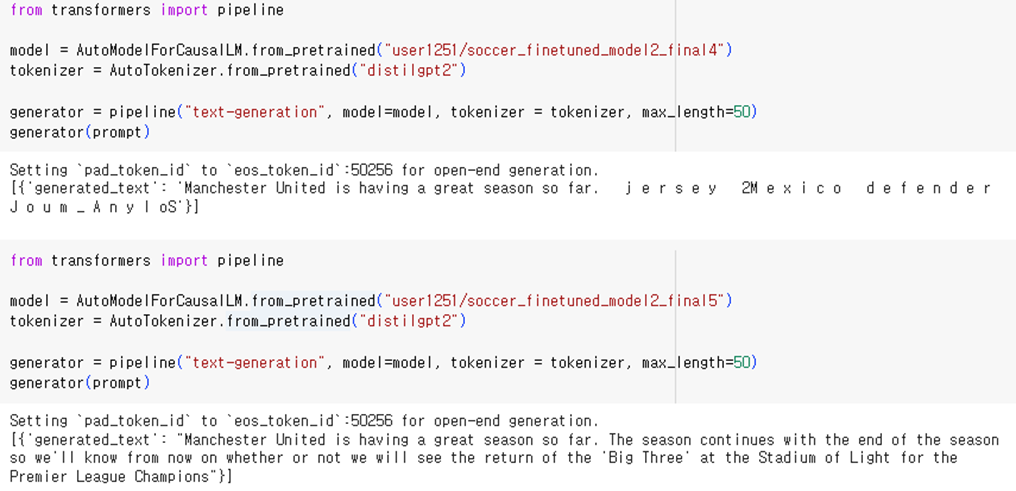
final4는 train set을 4000줄, test set을 1000줄로 하였다. 이번에도 final2와 동일한 문제가 발생하였다. 각 글자마다 간격이 벌어져 있는 오류가 발생하였고, prompt의 맥락과 관련된 내용을 출력해내지 못했다.
final5는 train set을 2000줄, test set을 500줄로 하였다. final5는 좋은 성능을 보여주었다. 다소 매끄럽지 않은 부분도 존재하나, 문장의 내용이 prompt의 맥락과 정확히 맞는다. final5가 우수한 성능을 보인다는 점과 final1에서 오류가 발생하지 않았다는 점을 고려했을 때, final2와 final4의 오류는 훈련에 사용한 데이터의 양이 너무 많아 발생한 것으로 추측된다.

Ⅲ 결론
이처럼 ‘socce_report_analysis’ 데이터셋과 ‘soccer-dialogues’ 데이터셋, ‘eli5’ 데이터셋을 사용하여 DistilGPT-2 모델을 fine-tuning 하여 보았다. 축구 관련 내용만을 모아놓은 두 데이터셋을 사용해 fine-tuning을 하면, 정말로 eli5 데이터셋을 사용했을 때에 비해 축구에 특화된 모습을 보일 수 있을지 궁금했기 때문이다.
실제로 eli5 데이터셋을 활용한 모델은 축구 관련 맥락을 전혀 이해하지 못하였다. 그러나 가장 자연스럽고 어법에 맞는 출력값을 보여주었다. 반면 socce_report_analysis을 활용한 모델은 간혹 맥락에 어긋나는 결과를 출력하기는 했으나, 대체적으로 prompt의 맥락에 맞는 결과들을 출력하며 실제로 축구에 특화된 성능을 보여주었다. 그러나 전혀 매끄럽지 않은 문장들만을 출력해 한계를 보였다. soccer-dialogues를 활용한 모델 역시 비슷한 문제점을 보였다. 완성 단계인 final5를 보면, prompt의 맥락에 맞는 결과를 출력하며 축구에 특화된 성능을 보여주기는 했으나, 문장 구성 능력에 큰 한계가 있었다.
따라서, 축구 관련 내용만을 모아놓은 ‘socce_report_analysis’ 데이터셋과 ‘soccer-dialogues’ 데이터셋을 사용해 fine-tuning을 하면, ‘eli5’와 같은 general한 데이터셋으로 fine-tuning했을 때보다 훨씬 축구에 특화된 성능을 가지게 된다. 그러나, 그 반대급부로 매끄러운 문장을 구성하는 능력이 하락하게 된다.
다음 연구에서는 문장 구성 능력을 유지하면서도 특정 분야에 특화된 성능을 보이도록 fine-tuning하는 방법을 고민하고자 한다. 또한, ‘soccer_finetuned_model2_final 계열’에서 훈련 데이터량이 특정 수준 이상으로 커지면 글자 사이 간격이 벌어지는 문제가 발생하는 정확한 이유를 고민하고자 한다.
Ⅳ 별첨
1. ‘ParsaKgvr/socce_report_analysis’ 데이터셋
2. ‘rony/soccer-dialogues’ 데이터셋
링크: https://huggingface.co/datasets/rony/soccer-dialogues/viewer/rony--soccer-dialogues/train?p=3304