경제학코딩2 11주차 - Tokenizer & Data Section
11주차에는 Tokenizer와 Data Section에 대해 배웠다.
강의에서 배운 사고의 흐름을 복습 및 정리하고자 한다.
1. Tokenizer
우선 다룰 것은 Tokenizer이다.
Tokenizer는 토큰화를 진행해주는 method이다.
아래의 그림을 보면 이해가 쉬울 것이다.
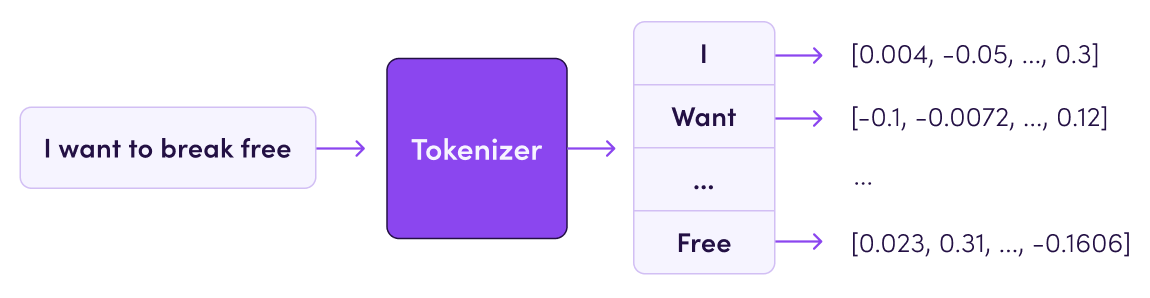
Code를 중심으로 살펴보도록 하겠다.
(1) 준비
!wget https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-103-raw-v1.zip
!unzip wikitext-103-raw-v1.zip
!pip install transformers
필요한 라이브러리 및 데이터셋을 준비하는 과정이다.
여러 번 반복해서 실행시켜도 unzip wikitext에서 넘어가지 않는 만큼,
이후의 출력 결과는 확인할 수 없었다.
https://www.youtube.com/watch?v=iJ3MqqDTKZw
이에, 어쩔 수 없이 김주철 교수님의 강의에 있는 결과를 캡처하였다.
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.pre_tokenizers import Whitespace
from tokenizers.trainers import BpeTrainer
필요한 class를 import 하였다.
(2) Why do we need train?
tokenizer = Tokenizer(BPE())
여기서 tokenizer = Tokenizer()나 tokenizer = Tokenizer(BPE)로 적지 않도록 유의해야 한다.
tokenizer.encode("Hello")
tokenizer.encode("Hello").ids
tokenizer.encode("Hello").tokens
Hello를 encoding하려고 했으나, tokenizer가 훈련되어 있지 않아 유의미한 결과를 얻지 못하였다.
그렇기 때문에 "train"이 필요한 것이다.
tokenizer.train(["./wikitext-103-raw/wiki.train.raw"])
tokenizer를 train 시키면, 위에서 encoding이 제대로 되지 않았던 문제를 해결할 수 있다.
그러나, 제대로 train이 완료되지 않고 자꾸 다운 되어 버린다.

이것은 왜 그런 것일까? 어떻게 해결해야 할까?
(3) Why do we need Whitespace Pre_tokenizer?
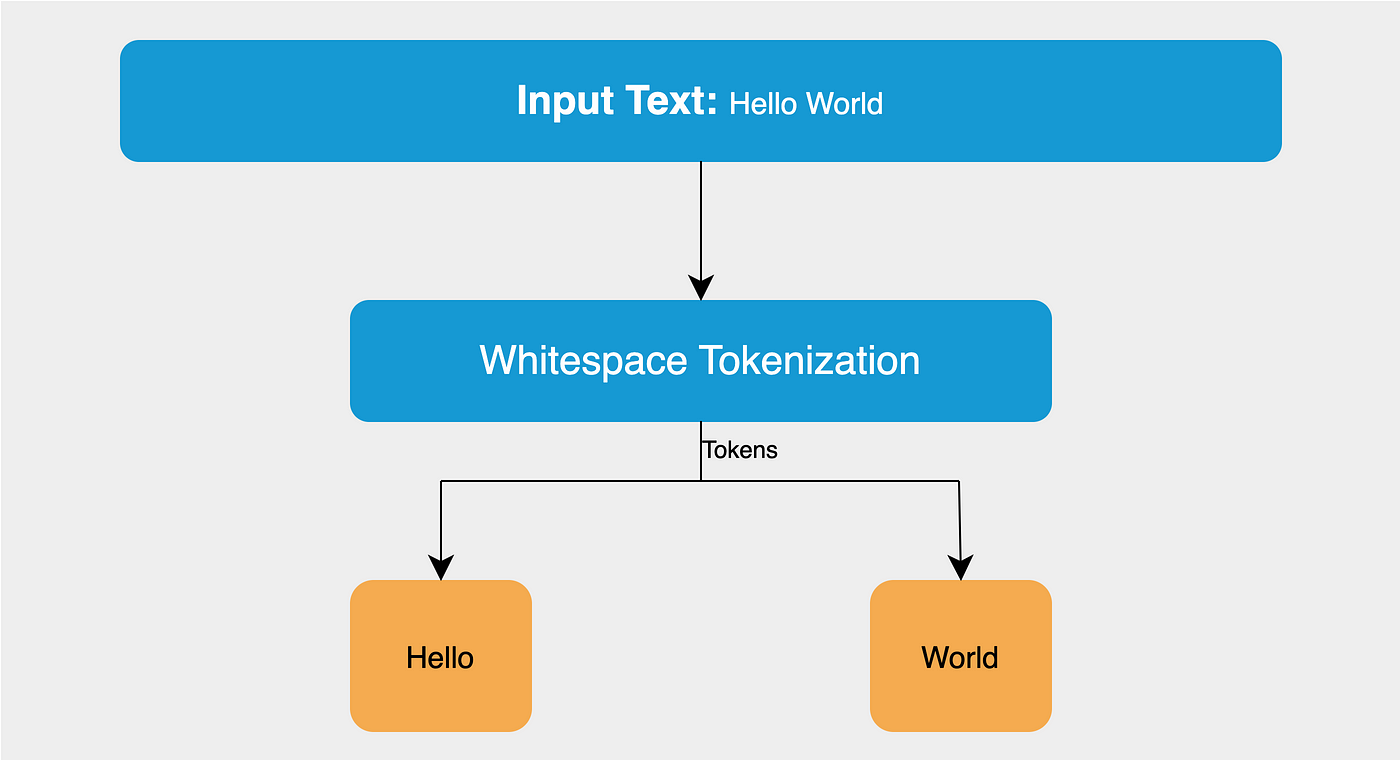
code를 살펴보기 전에, whitespace pretokenizer가 무엇인지부터 살펴보는 것이 필요하다.
whitespace는 말 그대로 "pre" tokenizer이다.
tokenizing 알고리즘이 적용되기 전에, 공백을 기준으로 텍스트를 분리해두는 역할을 한다.
즉, 더 명확하게 token을 식별하는 데 도움을 주고, gpu가 해야 할 연산의 양을 줄여준다.
그렇다면 code와 함께 왜 whitespace가 필요한지 살펴보도록 하곘다.
tokenizer = Tokenizer(BPE())
tokenizer.pre_tokenizer = Whitespace()
tokenizer.train(["./wikitext-103-raw/wiki.train.raw"])
tokenizer.encode("Hello, world!")
_.ids
tokenizer.save("./first.json")
위에서와 동일하게 train을 시켰다.
달라진 점이 있다면, whitespace pre_tokenizer를 하나 추가했다는 점이다.
whitespace를 하나 추가했을 뿐인데, 위에서는 되지 않았던 연산이 여기서는 수월하게 되는 것을 확인할 수 있다.
즉, whitespace는 연산량을 줄이기 위해서 필요한 것임을 확인할 수 있다.

(4) We need to init properly
하지만, 위의 연산에도 여전히 문제가 있다.
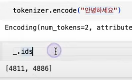
tokenizer.encode("안녕하세요")
_.ids
토큰 id를 출력해보면, '안'과 '하'만 반환이 되고 그 외에는 제대로 반환되지 않는 것을 볼 수 있다.
이것은 tokenizer가 '녕'과 '세', '요'를 몰라 무시했기 때문이다.
(5) Correct Version
tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
이 부분을 추가해 보았다.
tokenizer가 모르는 부분이 나오면, 솔직하게 모른다고 할 수 있게 해주는 역할이다.
tokenizer.pre_tokenizer = Whitespace()
tokenizer.train(["./wikitext-103-raw/wiki.train.raw"])
tokenizer.save("./second.json")
위의 부분을 추가하고, 다시 training을 시켰다.
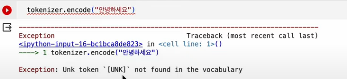
아는 부분은 제대로 표시해놓고, 모르는 부분은 모른다고 해야 하는데,
아예 에러가 출력되었다.
그렇다면 어떻게 해야 모르는 부분을 모른다고 표시한 채 출력할 수 있을까?
BPE trainer를 사용하는 것이다.
tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
tokenizer.pre_tokenizer = Whitespace()
trainer = BpeTrainer(vocab_size=30000, special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
files = [f"./wikitext-103-raw/wiki.{split}.raw" for split in ["test", "train", "valid"]]
tokenizer.train(files, trainer)
tokenizer.save("./tokenizer-wiki.json")
첫 두 줄은 동일하다.
다만, 여러 가지 special token을 추가하였고, test/train/valid 데이터셋으로 나누었다.
또한, train 과정에서 "BPE Trainer"를 사용하겠다고 명시하면서 변화를 주었다.
output = tokenizer.encode("Hello, 안녕하세요! How are you 😁 ?")
print(output.tokens)
다시 출력해보았다.
이번에는 모르는 부분은 "UNK"로 잘 출력되어 나왔다.
이모티콘이 있었음에도 에러가 나지 않고, UNK로 잘 출력되었다.

output = tokenizer.encode_batch(["Hello, world!", "How are you 😁 ?"])
이와 같이 길이가 다른 여러 문장이 있으면 어떻게 해야 할까?
tokenizer.enable_padding()
이 코드를 추가해주면 아래처럼 잘 되는 것을 볼 수 있다.

(6) Hugging Face Dataset
위에서 만든 tokenizer를 실제 dataset으로 적용해보았다.
!pip install datasets
from datasets import load_dataset
dataset = load_dataset("imdb")
hugging face에서 IMDb 리뷰 데이터셋을 불러왔다.
tokenizer = Tokenizer.from_file("./tokenizer-wiki.json")
temp = tokenizer.encode_batch(dataset["train"]["text"])
tokenizer.enable_padding()
tokenizer.enable_truncation(200)
temp = tokenizer.encode_batch(dataset["train"]["text"])
지금까지 한 것의 반복이다.
결과를 보면 다음과 같다


원 문장이 I rented I AM CURIOUS-YELLOW~였던 만큼,
45 21437 45으로 시작되는 토큰을 보면,
적절하게 encoding 되었음을 볼 수 있다.
2. Data Section
다음으로 다룰 것은 Data Section이다.
Data를 처리하는 방법에 대해 배울 것이다.
Code를 중심으로 살펴보도록 하겠다.
(1) 준비
!pip install -q keras-core
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import numpy as np
import keras_core as keras
from dataclasses import dataclass
!pip install -q transformers
!pip install -q datasets
필요한 라이브러리를 불러오는 과정으로, 특별한 것이 없다.
from datasets import load_dataset
dataset = load_dataset("imdb")
x_train = dataset["train"]["text"]
마찬가지로, 필요한 데이터셋을 불러오는 과정이다.
위의 Tokenizer에서 사용한 데이터셋과 동일하다.
(2) tokenizer 설정 및 encoding
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_pretrained("bert-base-uncased
tokenizer.enable_padding()
tokenizer.enable_truncation(1000)
temp = tokenizer.encode_batch(x_train)
x = [i.ids for i in temp]
기본적인 flow 및 원리는 위에서 한 것과 동일하다.
tokenizer와 padding, truncation을 활성화하였다.
다만, tokenizer를 직접 훈련시키는 대신,
BERT 기반의 pretrained된 tokenizer를 가져왔다.
(3) Data Loader 만들기
import torch
class MyDataset(torch.utils.data.Dataset):
def __init__(self, x, y):
self.x = x
self.y = y
def __getitem__(self, idx):
x = self.x[idx]
y = self.y[idx]
return torch.tensor(x), torch.tensor(y)
def __len__(self):
return len(self.x)
PyTorch의 Dataset class를 기반으로 MyDataset Class를 정의하였다.
MyDataset으로 Data Loader를 만들 것이기 때문이다.
이 class는 초기화 시에 토큰화된 x(text)와 y(label)을 받는다.
getitem method는 특정 index의 데이터를 가져오며,
len method는 데이터셋의 총 길이를 반환한다.
ds = MyDataset(x, y)
for i in ds[12400:12600]:
print(i)
MyDataset이 잘 만들어졌는지 확인하기 위해, 데이터셋 'ds'를 만들어 보았다.
12400번째부터 12600번째까지 print해보면, 정상적으로 잘 존재하는 것을 볼 수 있다.

dl = torch.utils.data.DataLoader(ds, batch_size=32, shuffle=True)
MyDataset에서 중요한 것은 데이터셋을 만드는 것이 아니라 DataLoader를 만드는 것이다.
dl은 DataLoader를 사용하여 만들어진 data loader이다.
batch의 크기는 32이며, shuffle=True를 통해 데이터를 섞도록 설정한다.
for i in dl:
print(i)
break
dl을 통해 생성된 첫 번째 batch를 출력해보면,
아래와 같이 잘 출력되는 것을 볼 수 있다.
dl에 문제가 없다는 것이다.

(4) Token Embedding
class Config:
vocab_size = tokenizer.get_vocab_size()
d_model = 5
여기서 정의해준 config class는, vocab size나 embedding vector의 차원 크기 등
embedding layer에 필요한 설정 값을 저장한다.
emb = keras.layers.Embedding(Config.vocab_size, Config.d_model)
emb(ds[0:1][0])
이 Config를 이용해 'emb'이라는 embedding layer를 생성해준 후,
위에서 불러온 데이터셋 ds의 첫 번째 샘플에 대해 embedding을 수행했다.

keras에 내장된 embedding layer를 사용하여 자동으로 생성한 것이니만큼,
embedding이 수월하게 잘 된 것을 확인할 수 있다.
class TokenEmbedding(keras.layers.Layer):
def __init__(self, config):
super().__init__()
self.tok_embbeding = keras.layers.Embedding(config.vocab_size, config.d_model)
def call(self, x):
x = self.tok_embbeding(x)
return x
위에서는 keras에 내장된 embedding layer를 사용했지만,
이번엔 일부 수동으로 embedding layer를 만들어보고자 한다.
우선, keras의 layer class를 기반으로 Token Embedding class를 정의해주었다.
이 class에서는 초기화 시 config를 받아 embedding layer를 설정한 후,
call method로 x에 대해 embedding을 설정했다.
a = TokenEmbedding(Config)
a(ds[0:3][0])
위에서 만든 TokenEmbedding을 바탕으로, 실제로 embedding을 수행해 보았다.
embedding이 잘 진행된 것을 확인할 수 있다.
