경제학코딩2 12주차 - Encoder
12주차에는 Encoder에 대해 배웠다.
강의에서 배운 사고의 흐름을 복습 및 정리하고자 한다.
Encoder는 무엇일까?
Transformer는 아래와 같은 과정을 거치는 Feed Forward Network이다.
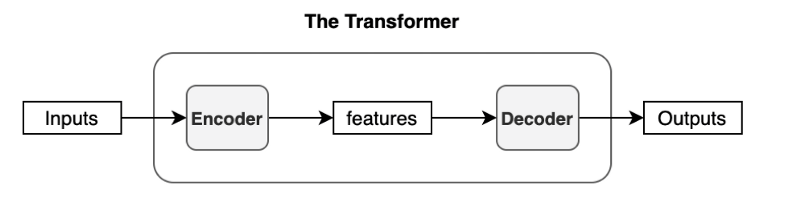
이때 Encoder 부분만 확대하면 아래와 같다.
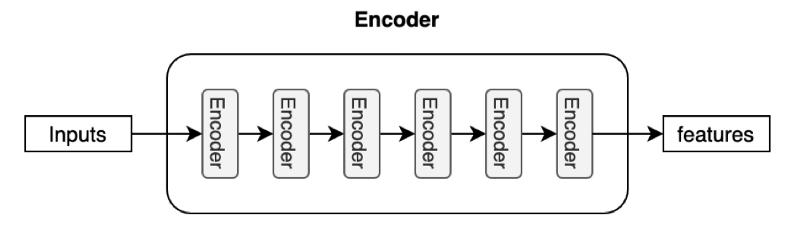
즉, Input을 받아 encoding 하는 역할을 수행하는 것이 Encoder인 것이다.
Encoder 안에는 여러 layer가 있고, 이 layer들을 모두 통틀어 encoder라고 한다.
구체적인 예시를 들어보도록 하겠다.
BERT라는 모델의 encoder 구조는 아래와 같다.
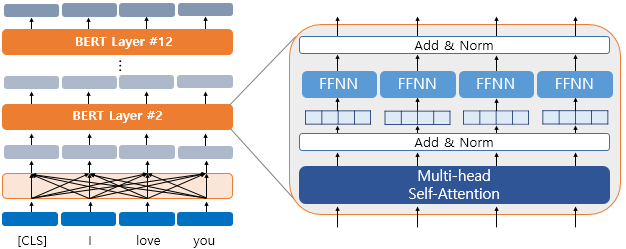
Keras Core Encoder
이제는 Code로 살펴보도록 하겠다.
(1) 준비
!pip install -q keras-core
import os
os.environ["KERAS_BACKEND"] = "torch"
import numpy as np
import keras_core as keras
from dataclasses import dataclass
이전 주차에서 배운 것의 반복이다.
(2) Data Class
class Config:
vocab_size : int = 1000
d_model : int = 512
block_size : int = None
num_heads : int = None
key_dim : int = None
dff : int = None
dropout_rate : float = None
num_layers : int = None
model에서 사용될 변수들을 Config라는 class 안에 정의하였다.
앞으로 계속 사용될 것이다.
(3-1) Token Embedding
temp = keras.layers.Embedding(Config.vocab_size, Config.d_model)
x = np.random.randint(0, 1000, (2, 5))
temp(x)
이 방식을 사용할 경우, embedding layer를 만들 수 있다.
작동 자체는 아래와 같이 잘 하는 것을 볼 수 있다.

class TokenEmbedding(keras.layers.Layer):
def __init__(self, config):
super().__init__()
self.config = config
self.tok_embedding = keras.layers.Embedding(config.vocab_size, config.d_model)
def call(self, x):
x = self.tok_embedding(x)
return x
그러나, 앞으로 효율적이고 수월하게 사용하기 위해선 이처럼 class로 만들어두는 것이 낫다.
temp = TokenEmbedding(Config)
x = np.random.randint(0, 1000, (2, 10))
temp(x)
이 방식 역시 작동을 잘 함을 확인할 수 있다.

아래 사진의 왼쪽이 encoder, 오른쪽이 decoder이다.
지금 한 것은, 왼쪽의 encoder에서 Input Embedding 부분을 수행하는 layer를 만든 것이다.
(3-2) Positional Embedding (& 기존의 token embedding)
class TokenAndPositionEmbedding(keras.layers.Layer):
def __init__(self, config):
super().__init__()
self.config = config
self.tok_embedding = keras.layers.Embedding(config.vocab_size, config.d_model)
self.pos_embedding = keras.layers.Embedding(config.block_size, config.d_model)
def call(self, x):
b, t = x.shape
tok_emb = self.tok_embedding(x)
pos_emb = self.pos_embedding(keras.ops.arange(self.config.block_size))
return tok_emb + pos_emb
위에서 Token Embedding을 수행하는 class를 만든 바 있다.
이 class를 조금 수정하여, positional embedding과 token embedding을 동시에 하는 class를 만들었다.
x = np.random.randint(0, 1000, (2, 10))
temp = TokenAndPositionEmbedding(Config)
temp(x)
잘 수행되는 것을 확인하였다.

아래 사진을 보면 이해가 쉽다.
지금 한 것은, Input Embedding과 Positional Encoding 부분을 수행하는 layer를 만든 것이다.
(4-1) The Global Self Attention Layer
class GlobalSelfAttention(keras.layers.Layer):
def __init__(self, config):
super().__init__()
self.config = config
self.mha = keras.layers.MultiHeadAttention(config.num_heads, config.key_dim)
self.layernorm = keras.layers.LayerNormalization()
self.add = keras.layers.Add()
def call(self, x):
attn_output = self.mha(query=x, value=x, key=x, use_causal=False)
x = self.add([x, attn_output])
x = self.layernorm(x)
return x
Multi-head Attention과 layer normalization 역할을 모두 수행하는 class이다.
input에 대해 attention을 수행한 후, 그 결과를 원래 input과 더한 뒤 정규화하였다.
아래 사진을 보면 이해가 쉽다.
Embdding을 지난 input은 두 갈래로 나뉜다.
한 갈래는 mult-head attention을 거쳐 normalization layer로 들어가고,
한 갈래는 바로 normalization layer로 들어간다.
이 두 갈래를 add하여 normalization을 취하는 것이 Global Self Attention Layer의 역할이다.
(4-2) The Feed Forward Network
class FeedForward(keras.layers.Layer):
def __init__(self, config):
super().__init__()
self.config = config
self.seq = keras.Sequential([
keras.layers.Dense(config.dff, activation='relu'),
keras.layers.Dense(config.d_model),
keras.layers.Dropout(config.dropout_rate)
])
self.add = keras.layers.Add()
self.layer_norm = keras.layers.LayerNormalization()
def call(self, x):
x = self.add([x, self.seq(x)])
x = self.layer_norm(x)
return x
Feed Forward Network를 구현하는 FeedForward class를 구현했다.
Dense Layer와 Dropout Layer, Layernormalization Layer까지 모두 포함시켰다.
아래 그림에서 보이다시피, add&norm에서 출발한 선이 두 갈래로 나뉜다.
한 갈래는 또다시 add&norm으로 바로 들어가고,
한 갈래는 FeedForward Layer를 거쳐 add&norm으로 들어간다.
FeedForward Class는 이를 구현한 것이다.
(4-3) The Enocder Layer
class EncoderLayer(keras.layers.Layer):
def __init__(self, config):
super().__init__()
self.config = config
self.gsa = GlobalSelfAttention(config)
self.ff = FeedForward(config)
def call(self, x):
x = self.gsa(x)
x = self.ff(x)
return x
Encoder Layer Class는, Global self attention layer와 FeedForward layer를 합친 것이다.
TokenAndPositionEmbedding layer -> Encoding Layer의 순서로 데이터가 처리되는 것이다.
TokenAndPositionEmbedding은 위에서 만들었던 것으로,
token embedding과 positional embedding을 수행한다.
(5) The Enocder
class Encoder(keras.layers.Layer):
def __init__(self, config):
super().__init__()
self.config = config
self.embedding = TokenAndPositionEmbedding(config)
self.enc_layers = [EncoderLayer(config) for _ in range(config.num_layers)]
self.dropout = keras.layers.Dropout(config.dropout_rate)
def call(self, x):
x = self.embedding(x)
x = self.dropout(x)
for i in range(self.config.num_layers):
x = self.enc_layers[i](x)
return x
앞에서 TokenAndPositionEmbedding layer -> Encoding Layer의 순서로 데이터가 처리된다고 말한 바 있다.
Enocder Class는 이 두 Layer를 합쳐, 마침내 하나의 Encoder를 완성시킨 것이다.
왼쪽 부분을 통째로 만든 것이라고 볼 수 있다.
(6) IMDB 데이터 적용
위에서 만든 Encoder에 실제 데이터셋을 적용하였다.
11주차에서도 사용한 적 있는 IMDB 데이터셋을 사용하였다.
!pip install -q datasets
from datasets import load_dataset
from tokenizers import Tokenizer
dataset = load_dataset("imdb")
IMDB 데이터셋을 불러오기 위해 dataset 라이브러리를 설치한 후, IMDB 데이터셋을 불러왔다.
11주차에서 배운 내용의 반복이다.
11주차 게시물의 2.Data Section을 들어가보면 더 자세한 내용을 확인할 수 있다.
tokenizer = Tokenizer.from_pretrained("bert-base-uncased")
tokenizer.encode_batch(dataset["train"]["text"])
tokenizer.enable_padding()
tokenizer.enable_truncation(1024)
temp = tokenizer.encode_batch(dataset["train"]["text"])
pre-trained된 BERT Tokenizer를 사용하여, 데이터셋의 text를 tokenizing 하였다.
가변 길이 sequence를 처리하기 위해 padding과 truncation도 활성화하였다.
이 역시 11주차에서 배운 내용의 반복이다.
11주차 게시물의 2.Data Section을 들어가보면 더 자세한 내용을 확인할 수 있다.
class MyDataset(torch.utils.data.Dataset):
def __init__(self, x, y):
super().__init__()
self.x = x
self.y = y
def __getitem__(self, idx):
x = self.x[idx]
y = self.y[idx]
return torch.tensor(x), torch.tensor(y)
def __len__(self):
return len(self.x)
x = [i.ids for i in temp]
y = dataset["train"]["label"]
ds = MyDataset(x, y)
dl = torch.utils.data.DataLoader(ds, batch_size=Config.batch_size, shuffle=True)
PyTorch의 Dataset Class를 기반으로 MyDataset Class를 정의하였다.
이 MyDataset을 class를 사용하여 dataloader 'dl'을 만들었다.
이것 역시 11주차에서 배운 내용이다.
11주차 게시물의 2.Data Section을 들어가보면 더 자세한 내용을 확인할 수 있다.
class MyModel(keras.Model):
def __init__(self, config):
super().__init__()
self.config = config
self.encoder = Encoder(config)
self.avg = keras.layers.GlobalAveragePooling1D()
self.final = keras.layers.Dense(1)
def call(self, x):
x = self.encoder(x)
x = self.avg(x)
x = self.final(x)
return x
이제 드디어 Model을 구축할 수 있게 되었다.
Keras를 사용해 custom model "MyModel"을 정의하였다.
앞에서 만든 Encoder를 사용하였고,
GlobalAveragePoling layer를 만들어,
시퀀스의 길이에 상관없이 고정된 크기의 벡터를 생성하게 하였다.
또한 self.final로 이진 분류 문제에 맞는 scalar 출력값을 생성하도록 하였다.
model = MyModel(Config)
앞에서 설정해둔 Config(hyperparameter setting)를 적용하여,
최종적으로 model을 완성하였다.
loss = keras.losses.BinaryCrossentropy(from_logits=True)
optimizer = keras.optimizers.Adam()
metrics = keras.metrics.BinaryAccuracy()
model.compile(optimizer=optimizer, loss=loss, metrics=[metrics])
loss에 Binary Crossentropy 손실 함수를 설정해 두었다.
optimizer에는 Adam Optimizer를 사용토록 설정해 두었다. 자세한 내용은 9주차에서 볼 수 있다.
metrics에는 Binary Accuracy metric을 설정하였다. 말 그대로 모델의 성능을 평가하는 데 사용된다.
이렇게 설정한 loss, optimizer, metrics를,
model.compile을 통해 model에 저장해두었다.
model.fit(dl, epochs=5)
드디어 train이 시작된 것이다.
앞에서 만들어둔 dataloader 'dl'을 사용하여,
dl로부터 불러와진 dataset을 기반으로 학습하도록 하였다.

직접 학습을 수행하여 결과를 확인하고 싶었으나,
GPU의 부재로 학습이 불가능하였다.
아무리 코드를 돌려봐도 44/782 이상으로는 진행되지 않았다.
따라서, model의 evaluation 부분은 code로만 설명하도록 하겠다.
eval_x = [i.ids for i in temp]
eval_y = dataset["test"]["label"]
eval_ds = MyDataset(eval_x, eval_y)
eval_dl = torch.utils.data.DataLoader(eval_ds, batch_size=128)
이 부분은 test datset을 사용하여 model의 성능을 평가하는 역할을 수행한다.
eval_x는 tokenize된 data에서 token의 id를 추출하여 저장한다. eval_x가 input으로 들어가면, 모델은 예측값을 생성한다.
eval_y는 test dataset의 label(정답)을 저장한다. 'eval_x가 input으로 들어가 나온 예측값'과 비교되어 model을 평가하는 데 사용된다.
eval_ds는 eval_x와 eval_y를 포함하는 test dataset을 생성한다.
eval_dl은 위에서 만든 test datset를 불러와 평가될 수 있게 해준다.
model.evaluate(eval_dl)
model의 유효성을 확인하고 실제로 사용하기 위해선, model의 성능 평가가 필수적이다.
앞에서 만든 'eval_dl'을 사용하여 model의 성능을 평가할 수 있다.
앞에서 말했듯, GPU의 부재로 model 학습이 불가능하였다.
따라서 직접 model evaluation을 수행하는 것 역시 불가능하였다.
다만 김주철 교수님께서 같은 코드로 수업을 진행하신 바 있으므로, 해당 화면을 캡처하여 사용하도록 하겠다.
https://www.youtube.com/watch?v=WlGot24oQ2M
아래의 사진이 훈련 과정에서의 accuracy(약 0.85 전후)와 loss(약 0.3 전후)를 나타낸다.
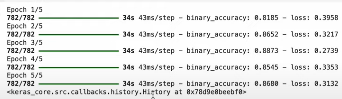
아래의 사진은 evaluation 과정에서의 accuracy(0.8436)와 loss(0.4339)를 나타낸다.
훈련 과정에서와 큰 차이가 없는 것을 확인할 수 있다.
accuracy 자체도 꽤 높다는 것을 고려하면,
우리의 model은 유효한 model로 판단할 수 있다.
