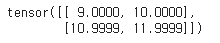경제학코딩2 13주차 - Scaled_dot_product_attention

Attention is all you need
13주차에는 "Attention is all you need" 논문을 바탕으로 scaled dot product와 attention mask에 대해서 배웠다.
강의에서 배운 사고의 흐름을 복습 및 정리하고자 한다.
1. Scaled Dot Product
Scaled Dot-Product는 transformer를 이해하는 데 필수적이다.
그 원리는 아래와 같다.
Scaled Dot-Product attention 방식에서는 Query, Key, Value가 input으로 들어온다.
이때 Q와 K의 dot product를 통해 attention score를 계산하면,
이를 scaling 하여 softmax를 적용한 후, 결과에 V를 적용하게 된다.
그림을 통해 원리를 이해한 만큼, Python Code를 따라가며 내용을 복습하고자 한다.
code에서는 여러 가지 방식으로 scaled dot-product attention을 계산하였다.
(1) 방식 1: pytorch로 Scaled Dot-Product Attention을 계산
Q = torch.tensor([[1, 2], [3, 4]]).float()
K = torch.tensor([[5, 6], [7, 8]]).float()
V = torch.tensor([[9, 10], [11, 12]]).float()
여기서 `Q`, `K`, `V`는 각각 Query, Key, Value를 나타내는 행렬이다.
float() 함수는 이들을 부동소수점 숫자로 변환한다.
F.scaled_dot_product_attention(Q, K, V)
이 부분은 PyTorch의 함수를 사용하여 Scaled Dot-Product Attention을 계산한다.
이러한 결과가 나왔다.

(2) 방식2: 원래 원리대로 Scaled Dot-Product Attention을 계산
Q @ K.transpose(-2, -1)
torch.softmax(Q @ K.transpose(-2, -1), dim=1)
Softmax 함수를 적용하여 attention weight를 계산했다.
여기서 dim=1은 행에 대해 softmax를 적용한다는 뜻이다.
torch.softmax(Q @ K.transpose(-2, -1), dim=1) @ V
Softmax로 얻은 weight를 Value 행렬에 적용하여 최종 attention 값을 얻었다.
위에서의 결과와 사실상 동일하나, 수동으로 계산하다 보니 오차가 있다.
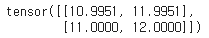
(3) 방식3: 원래 원리대로 Scaled Dot-Product Attention을 계산 but 계산만 매끄럽게
import math
math.sqrt(Q.size(-1))
여기서는 math를 이용해 transpose를 하였다.
torch.softmax((Q @ K.transpose(-2, -1) / math.sqrt(Q.size(-1))), dim=-1)
Query와 Key의 dot product를 scaling하고 Softmax를 적용하였다.
torch.softmax((Q @ K.transpose(-2, -1) / math.sqrt(Q.size(-1))), dim=-1) @ V
scaling된 Softmax weight를 Value 행렬에 적용하여 최종 attention 값을 얻었다.
계산적 오차가 사라지니 원 결과와 동일해지는 것을 확인할 수 있다.
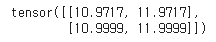
(4) 결론: pytorch로 Scaled Dot-Product Attention을 계산하는 것이 가장 편하다
query = torch.rand(1, 3, 2, dtype=torch.float)
key = torch.rand(1, 3, 2, dtype=torch.float)
value = torch.rand(1, 3, 2, dtype=torch.float)
F.scaled_dot_product_attention(query, key, value)
앞의 3가지 방식은 모두 같은 결과를 가져왔다.
그렇다면 가장 간단한 방식을 사용하는 것이 나을 것이다.
그래서 최종 결론을 내 보았다.
첫 번째 방식을 사용하되, 코드를 약간 변형하여 랜덤한 Query, Key, Value tensor를 생성하도록 하였다.
당연히 결과는 매번 달라질 것이나, 첨부해 보았다.

2. Attention Mask
Attention Mask 역시 transformer를 이해하는 데 필수적이다.
그 원리는 아래와 같다.
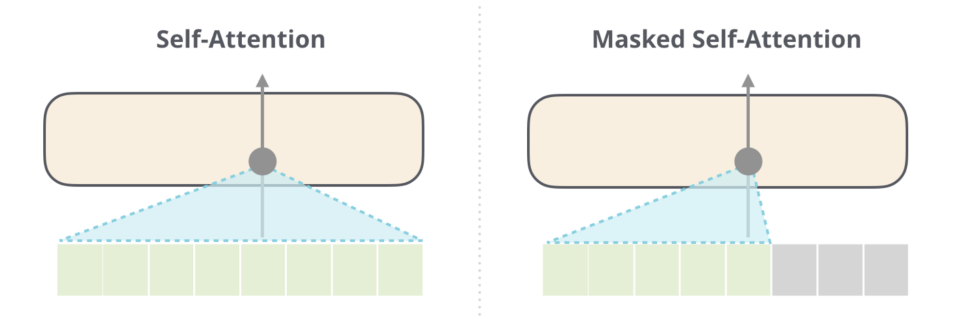
GPT와 같이 decoder만 있는 모델들은, 학습 과정에서 이전 단어들을 통해 다음 단어들을 예측한다.
따라서 i번쨰 단어를 학습할 때 i번째 이후의 단어는 학습에 포함시키지 않는다.
i번째 이후의 단어가 학습에 포함되지 않도록 하는 것을 attention mask라고 한다.

그림을 통해 원리를 이해한 만큼, Python Code를 따라가며 내용을 복습하고자 한다.
attn_mask = torch.ones(2, 2).tril(diagonal=0)
이 attention mask는 대각선 부분을 0으로 바꾼다.
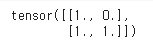
하지만, 이대로 진행을 이어가면 원하는 결과를 얻을 수 없다.
왜 그럴까? 이 상태에다가 softmax를 취해야 하므로,
-inf가 되어야 mask가 된다.
attn_mask = attn_mask.masked_fill(attn_mask == 0, -float('inf'))
따라서 제대로 mask가 되려면 이 코드를 써야 한다.
출력 결과는 아래와 같다.
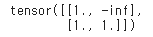
torch.softmax(attn_mask, dim=-1)
기존의 잘못된 attn_mask(attn_mask = torch.ones(2, 2).tril(diagonal=0))를 softmax 시키면 아래와 같다.
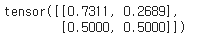
고친 attn_mask(attn_mask = attn_mask.masked_fill(attn_mask == 0, -float('inf')))를 softmax 시키면 아래와 같다.
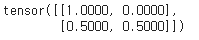
두 번째 코드를 적용해야 0.00으로 masking이 제대로 이루어진 것을 확인할 수 있다.
위에서 배운 scaled dot-product와 attention mask를 결합할 수 있다
이때 위에서와 마찬가지로, 여러 가지 방식으로 이를 수행하였다.
세 방식 모두 결과는 동일하다.
(1) 방식 1: Scaled Dot-Product & attention mask 수동으로 적용
torch.softmax((Q @ K.transpose(-2, -1) / math.sqrt(Q.size(-1))) + attn_mask, dim=-1) @ V
math library를 이용해 scaled-dot product를 수동으로 계산하였다.
attention mask 역시 수동으로 계산한 attn_mask를 사용하였다.
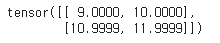
(2) 방식 2: Scaled Dot-Product은 pytorch로 계산, attention mask는 수동으로 적용
F.scaled_dot_product_attention(Q, K, V, attn_mask=attn_mask)
pytorch를 이용해 scaled-dot product를 자동으로 계산하였다.
다만 attention mask는 여전히 수동으로 계산한 attn_mask를 사용하였다.
결과 자체는 위와 동일함을 확인할 수 있다.
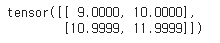
(3) 방식 3: Scaled Dot-Product & attention mask 자동으로 적용
F.scaled_dot_product_attention(Q, K, V, is_causal=True)
pytorch를 이용해 scaled-dot product를 자동으로 계산하였다.
Attention mask도 수동으로 계산한 attn_mask이 아닌, pytorch의 casual mask를 사용하였다.
결과 자체는 위와 동일함을 확인할 수 있다.