14주차에는 Decoder에 대해 배웠다.
강의에서 배운 사고의 흐름을 복습 및 정리하고자 한다.
Decoder는 무엇일까?
Transformer는 아래와 같은 과정을 거치는 Feed Forward Network이다.
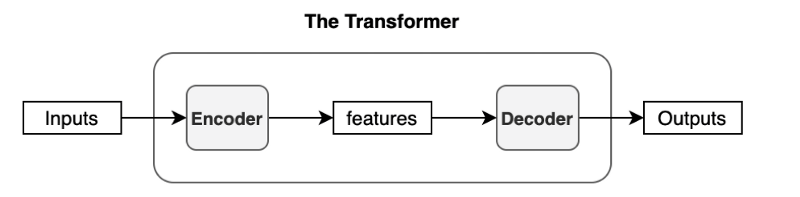
이때 조금 확대해서 보면 아래와 같다.
오른쪽이 Decoder이다.
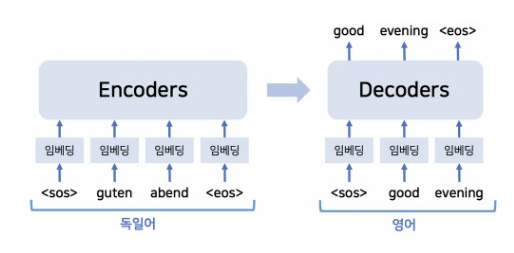
즉, 이전 단계로부터 data를 받아 output을 출력하는 역할을 수행하는 것이 Decoder 인 것이다.
Decoder 안에는 여러 layer가 있고, 이 layer들을 모두 통틀어 Decoder라고 한다.
Code로 보는 Decoder
이제는 Code로 살펴보도록 하겠다.
import torch
import torch.nn as nn
from torch.nn import functional as F
!wget 부분은 github 저장소에서 text file을 다운로드 하는 역할을 수행한다.
크게 언급할 만한 부분은 없다.
batch_size = 32
block_size = 8
max_iters = 3000
learning_rate = 1e-3
device = "cuda" if torch.cuda.is_available() else "cpu"
n_emb = 32
이 부분은 hyperparameter들을 지정해두는 역할이다.
batch 크기, block 크기, 반복 횟수, 학습률, gpu/cpu, embedding 크기 등을 지정하였다.
with open("input.txt", "r", encoding="utf-8") as f:
text = f.read()
print(text[:300])
다운로드한 text file을 열어 보았다.
text로 연 후, 첫 300자를 출력해보았다.
아래와 같이 정상적으로 잘 출력되는 것을 볼 수 있다.

chars = sorted(list(set(text)))
입력된 text에서 모든 고유 문자를 추출하여 chars라는 list에 저장하였다.
set(text)는 중복을 제거한 문자들의 집합이고, sorted(list(set(text)))는 그 집합을 알파벳 순의 리스트로 바꾼다.
즉, chars는 text에 포함된 모든 고유 문자를 알파벳 순으로 정렬한 list이다.
chars
chars를 출력해보면 아래와 같다.
너무 길어 마지막 소문자 부분은 잘렸지만,
대문자/소문자 A~Z는 물론이고 특수문자까지 list에 있는 것을 확인할 수 있다.
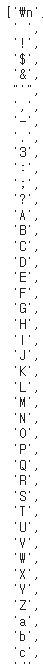
vocab_size = len(chars)
vocab_size는 model이 인식할 어휘의 수를 결정한다.
'chars' list의 길이만큼 인식하므로, 영어 외의 언어는 알아들을 수 없을 것이다.
stoi = {ch: i for i, ch in enumerate(chars)}
itos = {i: ch for i, ch in enumerate(chars)}
stoi는 string-to-index의 줄임말이다.
즉, 각 문자를 해당하는 index(숫자)로 mapping하는 것이다.
iots는 index-to-string의 줄임말이다.
모델의 출력을 다시 문자로 반환하는 데 사용된다.
stoi['a']
itos[39]
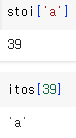
위의 예시를 보면 stoi와 itos를 더 잘 이해할 수 있다.
stoi를 통해 알파벳 'a'를 39번 index로 변환할 수 있다.
itos에 39를 넣어주면 이를 다시 알파벳 'a'로 변환할 수 있다.
encode = lambda s: [stoi[c] for c in s]
decode = lambda x: "".join([itos[i] for i in x])
stoi는 문자를 숫자로 바꾸는 것이므로, encode에 사용될 것임을 예상할 수 있다.
encode 함수는 문자열을 받아 각 문자를 해당하는 index로 변환하는 역할을 수행한다.
stoi와의 차이점은, stoi는 하나하나씩 변환하는 데 사용된다면, encode는 여러 문자를 한 번에 변환할 수 있다는 것이다.
마찬가지로, itos는 숫자를 문자로 바꾸는 것이므로, decode에 사용될 것임을 예상할 수 있다.
decode 함수는 index의 list를 받아, 이를 다시 문자열로 변환하는 역할을 수행한다.
itos와의 차이점 역시 encode 함수에서와 동일하다. decode 함수를 통하면 한 번에 처리할 수 있다는 장점이 있다.
text[0:100]
decode(encode(text[0:100]))
이 코드를 실행해보면, encode와 decode가 잘 만들어졌는지 확인해볼 수 있다.
아래에서 보이는 것과 같이 문자열이 encode된 후 다시 decode되면 원래의 문자열과 동일해지므로,
encode와 decode 함수 둘 다 문제없음을 알 수 있다.

data = torch.tensor(encode(text), dtype=torch.long)
n = int(0.9*len(data))
train_data = data[:n]
val_data = data[n:]
주어진 text가 encode 함수를 통해 숫자로 encoding 되면, data에 저장되도록 하였다.
이후, 전체 데이터셋의 90%는 훈련용으로, 나머지 10%는 검증용으로 사용되도록 설정하였다.
def get_batch(split):
data = train_data if split == "train" else val_data
ix = torch.randint(len(data)-block_size, (batch_size,))
x = torch.stack([data[i:i+block_size] for i in ix])
y = torch.stack([data[i+1:i+block_size+1] for i in ix])
x, y = x.to(device), y.to(device)
return x, y
get_batch함수는 train/val dataset에서 batch를 생성하는 역할을 한다.
(split) 부분에 train이 입력되면 train set에 대해서 batch를 생성하고,
(split) 부분에 그 외의 것이 입력되면 validation set에 대해서 batch를 생성하게 하였다.
최종적으로 x와 y batch를 반환한다.
xb, yb = get_batch('train')
xb, yb
train set에 대해서 생성된 batch를 xb와 yb로 저장하였다.
아래의 사진을 보면 get_batch 성공적으로 잘 이루어졌음을 확인할 수 있다.
사진이 너무 길어 아랫부분이 잘리기는 하였다.

class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
self.k = nn.Linear(n_emb, head_size, bias=False)
self.q = nn.Linear(n_emb, head_size, bias=False)
self.v = nn.Linear(n_emb, head_size, bias=False)
def forward(self, x):
B, T, C = x.shape
k = self.k(x)
q = self.q(x)
v = self.v(x)
out = F.scaled_dot_product_attention(q, k, v, is_causal=True)
return out
Head class는 multi-head attention의 각 head를 나타낸다.
query, key, value vector를 생성하고 attention을 계산하는 것이다.
아래 사진을 보면 multi-head attention이 설명되어 있는데,
여러 block이 뒤로 중첩되어 있는 것을 볼 수 있다.
중첩되어 있는 block 하나하나가 head이다.
즉, 위에서 정의한 'head'는 multi-head를 구성하는 수많은 head 중 하나이다.

class MultiHeadAttention(nn.Module):
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
def forward(self, x):
return torch.cat([h(x) for h in self.heads], dim=-1)
위에서 만든 head를 모두 합쳐, multi-head가 되도록 하는 부분이다.
이러한 방식을 채택하면, 여러 개의 head가 동시에 다른 부분을 주의 깊게 볼 수 있게 해준다.
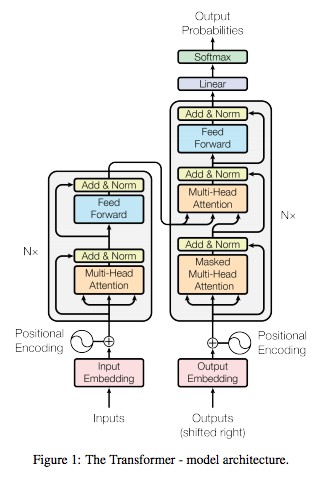
즉, 오른쪽의 decoder에서 multi-head attention을 나타내는 것이다.
class FeedForward(nn.Module):
def __init__(self, n_emb):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_emb, n_emb),
nn.ReLU()
)
def forward(self, x):
return self.net(x)
FeedForward Class는 FeedForward Network를 구현한다.
각 block에 비선형 변환을 적용한다.
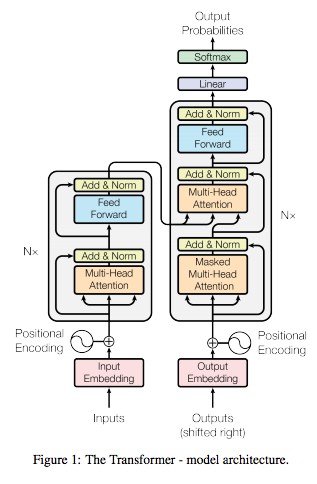
즉, 오른쪽의 decoder에서 Feed Forward을 나타내는 것이다.
class Block(nn.Module):
def __init__(self, n_emb, n_head):
super().__init__()
head_size = n_emb // n_head
self.sa = MultiHeadAttention(n_head, head_size)
self.ffwd = FeedForward(n_emb)
self.ln1 = nn.LayerNorm(n_emb)
self.ln2 = nn.LayerNorm(n_emb)
def forward(self, x):
x = x + self.sa(self.ln1(x))
x = x + self.ffwd(self.ln2(x))
return x
Block class는 transformer의 각 block을 나타낸다.
위에서 만든 multihead attention block과 feed forward block을
이 block이라는 class 안에 다 넣은 것이다.
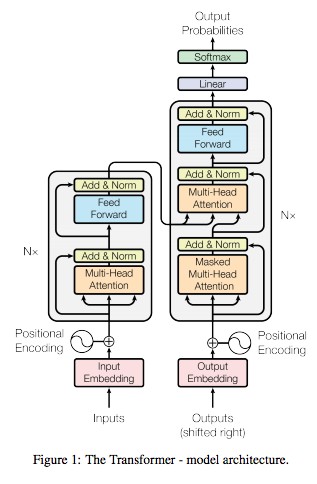
즉, 오른쪽의 decoder에서 각각의 네모 block을 나타내는 것이다.
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.tok_emb = nn.Embedding(vocab_size, n_emb)
self.pos_emb = nn.Embedding(block_size, n_emb)
self.blocks = nn.Sequential(
Block(n_emb, n_head=4),
Block(n_emb, n_head=4),
Block(n_emb, n_head=4),
)
self.lm_head = nn.Linear(n_emb, vocab_size)
def forward(self, idx, targets=None):
B, T = idx.shape
tok_emb = self.tok_emb(idx)
pos_emb = self.pos_emb(torch.arange(T, device=device))
x = tok_emb + pos_emb
x = self.blocks(x)
logits = self.lm_head(x)
if targets == None:
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss
def generate(self, idx, max_new_tokens):
for _ in range(max_new_tokens):
idx_cond = idx[:,-block_size:]
logits, loss = self(idx_cond)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, idx_next), dim=1)
return idx>
SimpleModel class는 PyTorch의 nn.Module을 상속받아, 지금까지 만들었던 class들을 총 규합한다.
크게 init, forward, generate로 나뉜다.
먼저, init은 method의 구성 요소를 초기화한다.
여기에서는 token embedding, positional embedding, block, head가 초기화된다.
특히 tok_emb와 pos_emb는 nn.Embedding을 통해 구현되며,
입력 토큰과 그 위치에 따라 각각 다른 벡터 표현을 생성하는 역할을 맡는다.
자세한 내용은 9주차 글에 있다.
다음으로, forward method는 model이 input data를 어떻게 처리할지 정의한다.
forward에서는 token embedding과 positional embedding이 결합된 후,
block(위에서 정의한 multi-head attention, feed forward 및 normalization layer)들을 거치게 된다.
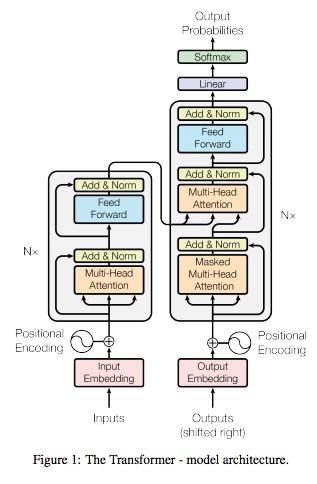
즉, 'forward'는 오른쪽 decoder에서,
+로 표시된 부분에서 시작해 Linear 전의 부분까지 올라가는 역할을 수행한다.
마지막으로, generate는 현재의 index와 생성할 새 token의 최대 개수를 입력으로 받아,
최종적으로 생성된 token sequence를 반환한다.
max new token만큼의 새 토큰을 생성하기 위해 loop가 반복되고 있는데,
이 loop 안에서
idx_cond(input index의 마지막 block_size를 추출해 저장),
logits(idx_cond에 대한 logit값 계산 및 마지막 토큰에 대한 logit만을 추출),
probs(softmax를 통해 logit을 확률로 변환),
idx_next(무작위로 다음 token의 index 선택),
idx(새로 선택된 token을 기존의 index sequence에 추가)
가 계속 반복되면서 최종적으로 생성된 token sequence idx가 반환된다.

즉, 오른쪽 decoder에서
Linear 부분에서 시작해 맨 윗부분까지를 담당하는 것이다.
model = SimpleModel().to(device)
m = model
logits, loss = m(xb, yb)
optimizer = torch.optim.AdamW(m.parameters(), lr=learning_rate)
위에서 만든 SimpleModel을 바탕으로, 'model'을 만들었다.
보다 쉽게 부를 수 있도록 m으로 다시 명명했다.
이후 Adam optimzer를 사용해 model parameter를 업데이트하도록 하였다.
for iter in range(max_iters):
xb, yb = get_batch('train')
logits, loss = m(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
if iter % 200 == 0:
print(iter, loss.item())
드디어 실제 train이 시작되는 부분이다.
이 loop에서는 model m을 max_iters 만큼 반복 학습시킨다.
처음에 만든 get_batch를 사용해 train data에서 무작위로 배치를 선택하게 한 후,
loigits, loss부분을 통해 예측을 수행하고, 손실을 계산하도록 하였다.
optimizer의 gradient를 초기화한 후,
손실에 대한 gradient를 계산하여 optimizer에 parameter를 업데이트하게 하였다.
마지막 if 부분은 200번째 반복마다 현재 손실을 출력하게 한다.
꼭 필요한 부분은 아니지만, 훈련이 잘 되고 있는지 판단하게 해준다.
출력해보면, loss가 점점 줄어들고 있는 것을 볼 수 있다.
즉, train이 잘 되어가고 있다는 뜻이다.

context = torch.zeros((1,1), dtype=torch.long, device=device)
print(decode(m.generate(context, max_new_tokens=1000)[0].tolist()))
context는 model m이 text를 생성하기 시작할 초기 context를 만드는 역할이다.
여기서는 1x1 크기의 0으로 초기화된 tensor를 사용하였다.
context를 만든 후, m.generate(context, max_new_tokens=1000)를 통해 1000개의 새 token을 생성하게 하였다.
생성된 token은 decode를 지나 text로 변환된다.
print를 통해 이를 실행시키면 아래와 같다.

영어 알파벳들이 생성되었지만, 말이 되지 않는 알파벳들의 나열 뿐이다.
그나마 고무적인 것은, dataset의 형식과 다소 유사하다는 것이다.
앞에서도 보인 적이 있지만, 우리가 사용한 data set은 아래의 사진과 같다.

출력 결과물과 유사하게, : 표시 후 한 줄을 띄우는 형태가 자주 등장함을 알 수 있다.
즉, 훈련을 반복해서 여러 번 수행하면, 점점 더 loss가 줄어들고 정확도가 높아질 것임을 예상할 수 있다.
추후 Colab을 구매하거나 GPU가 있는 PC를 마련한다면,
훈련을 여러 번 반복해서 출력물이 어떻게 달라지는지,
과연 말이 되는 결과가 출력되는지 확인해보고자 한다.
'Coding' 카테고리의 다른 글
| 경제학코딩1 – Final Project: Part 1 (0) | 2024.01.25 |
|---|---|
| In-Context Learning & Chain-of-Thought Prompting (2) | 2024.01.23 |
| 경제학코딩2 13주차 - Scaled_dot_product_attention (0) | 2024.01.21 |
| 경제학코딩2 12주차 - Encoder (0) | 2024.01.20 |
| 경제학코딩2 11주차 - Tokenizer & Data Section (0) | 2024.01.20 |